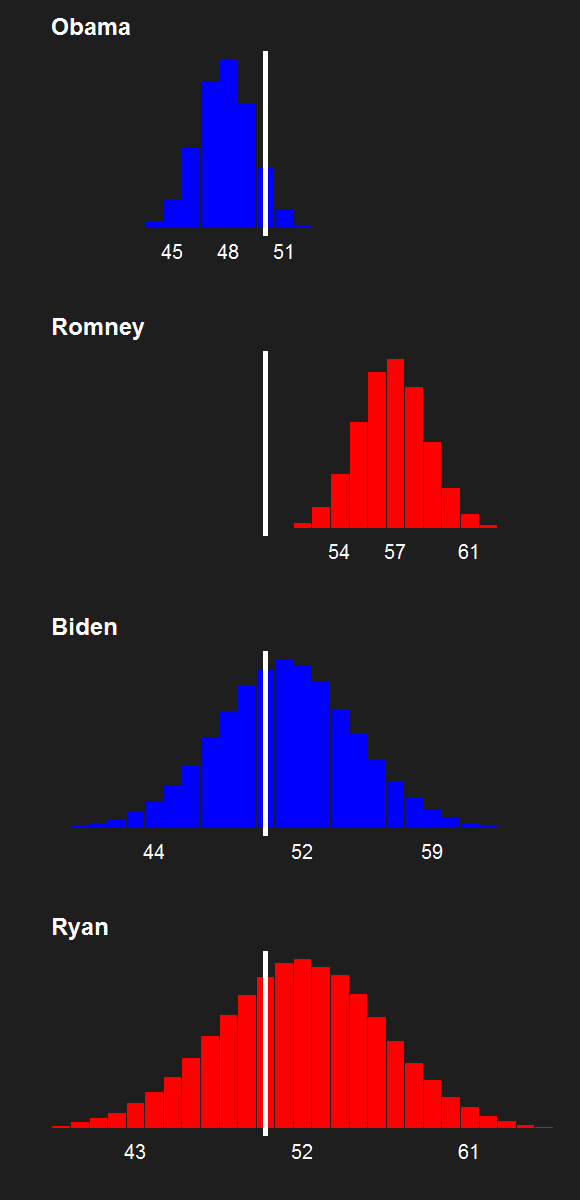
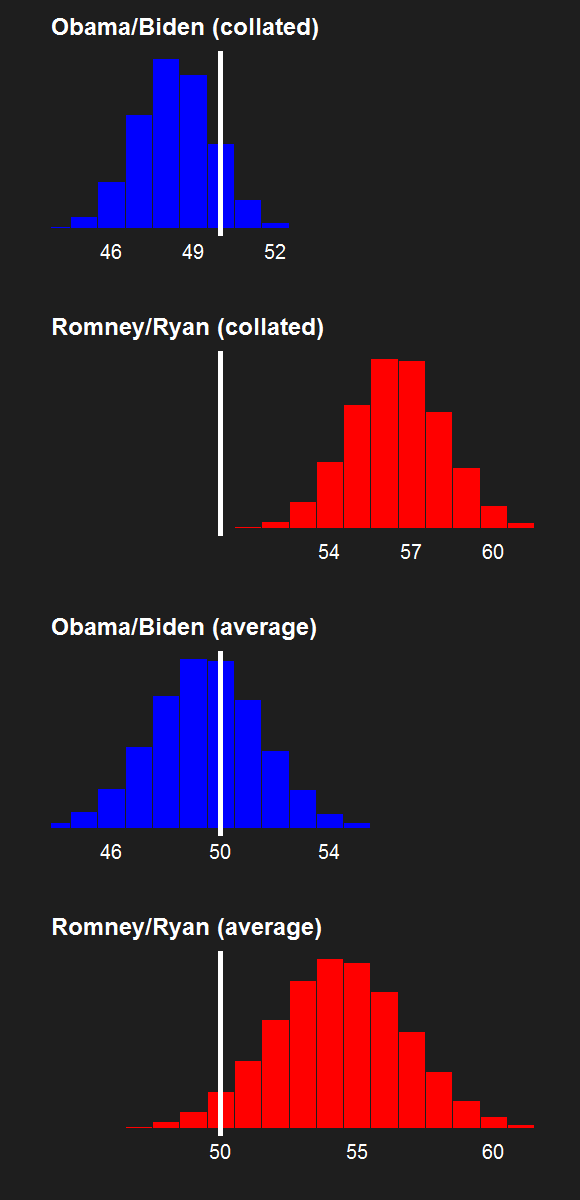
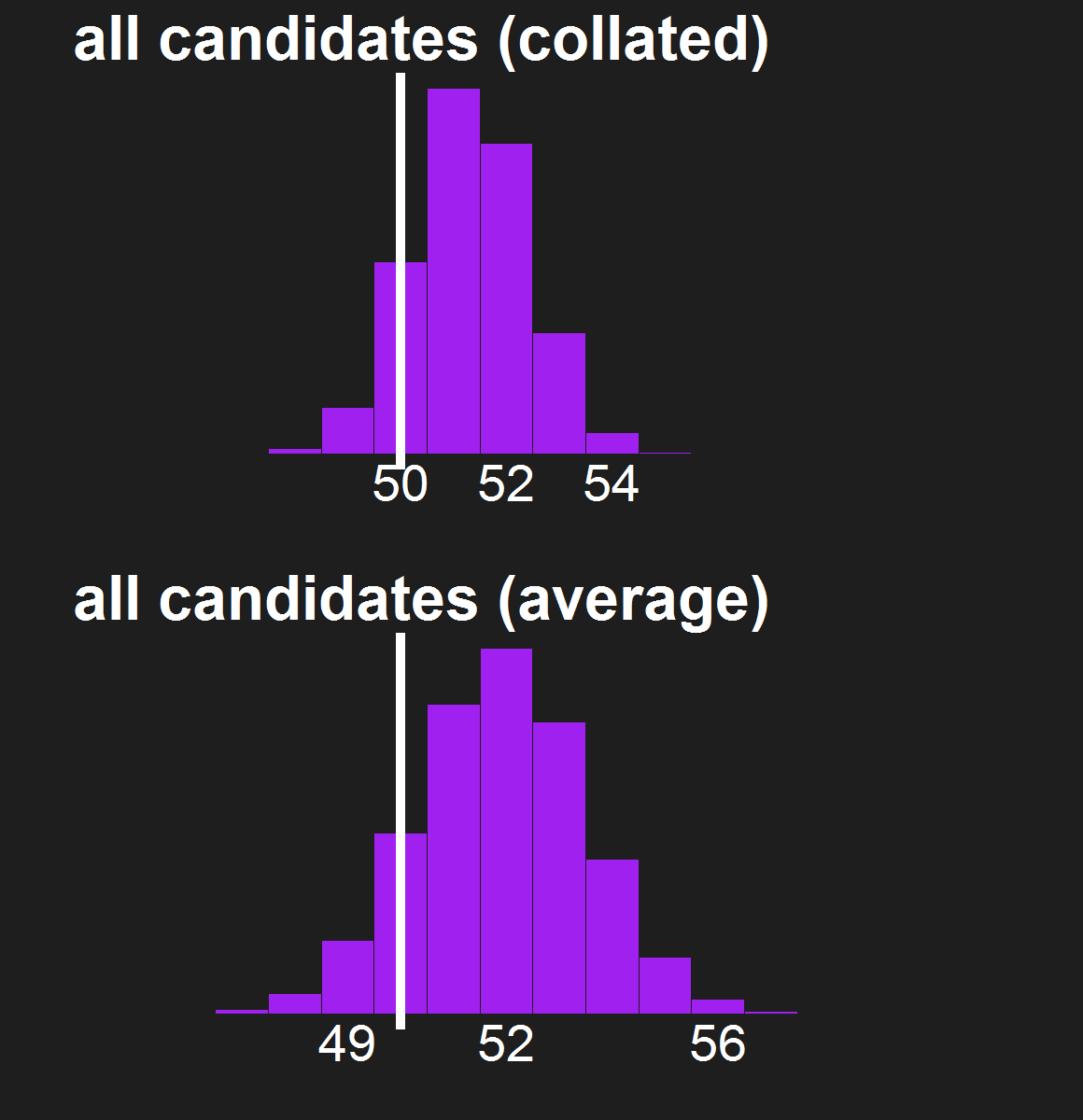
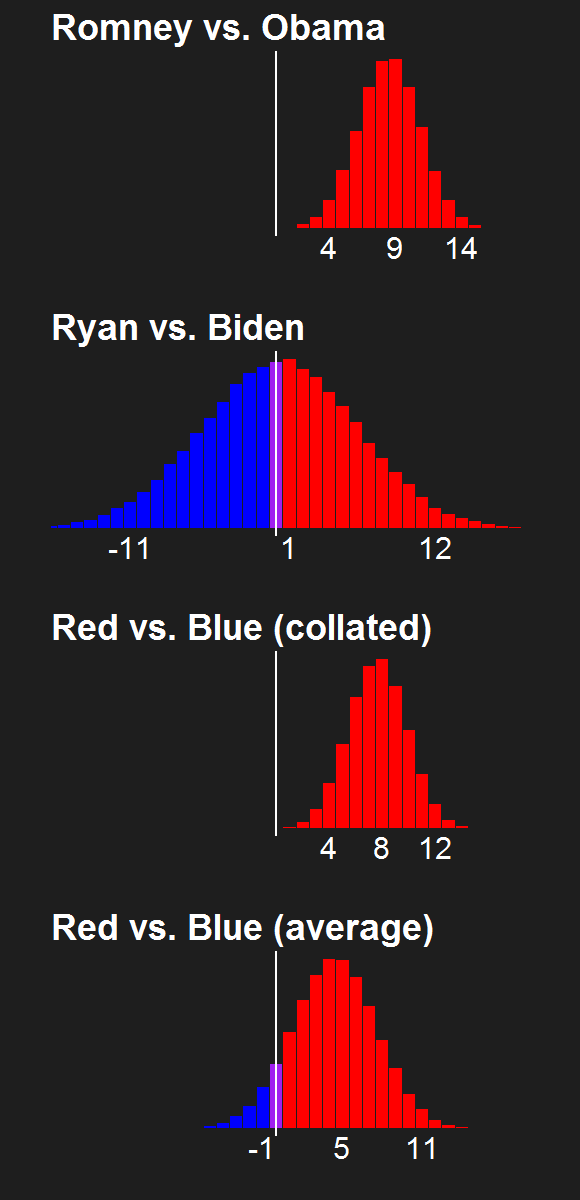
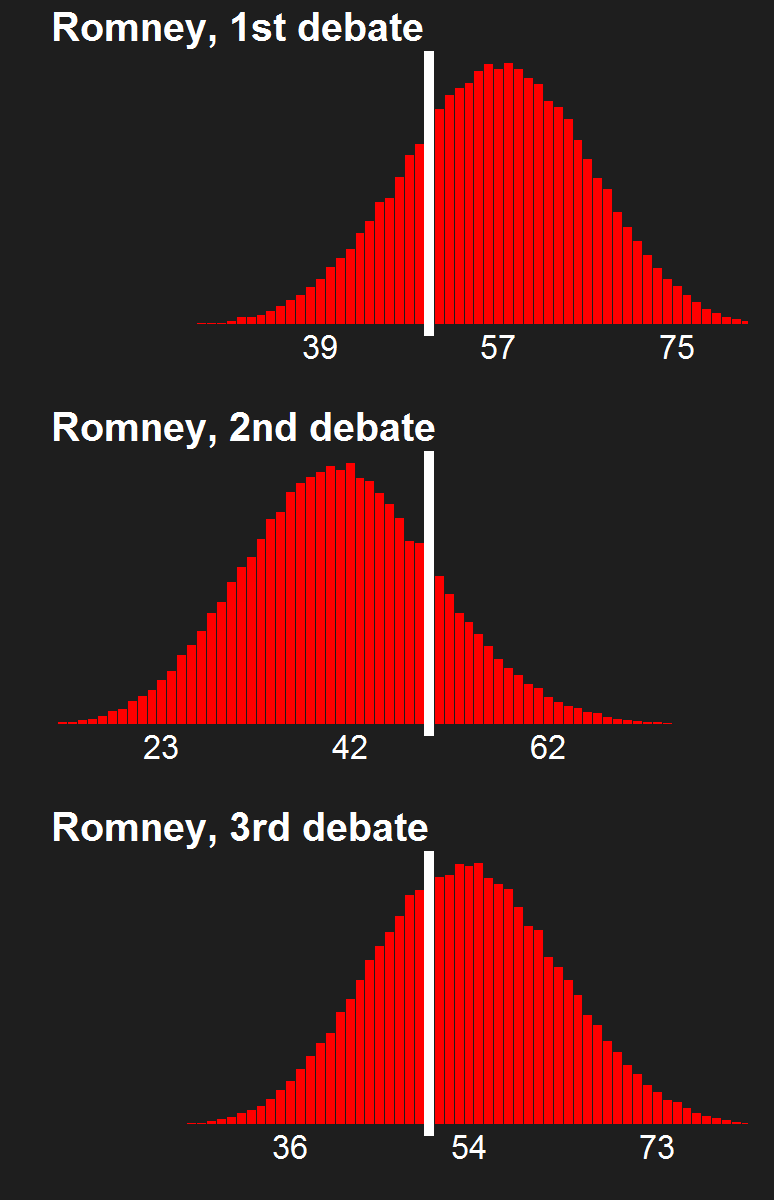
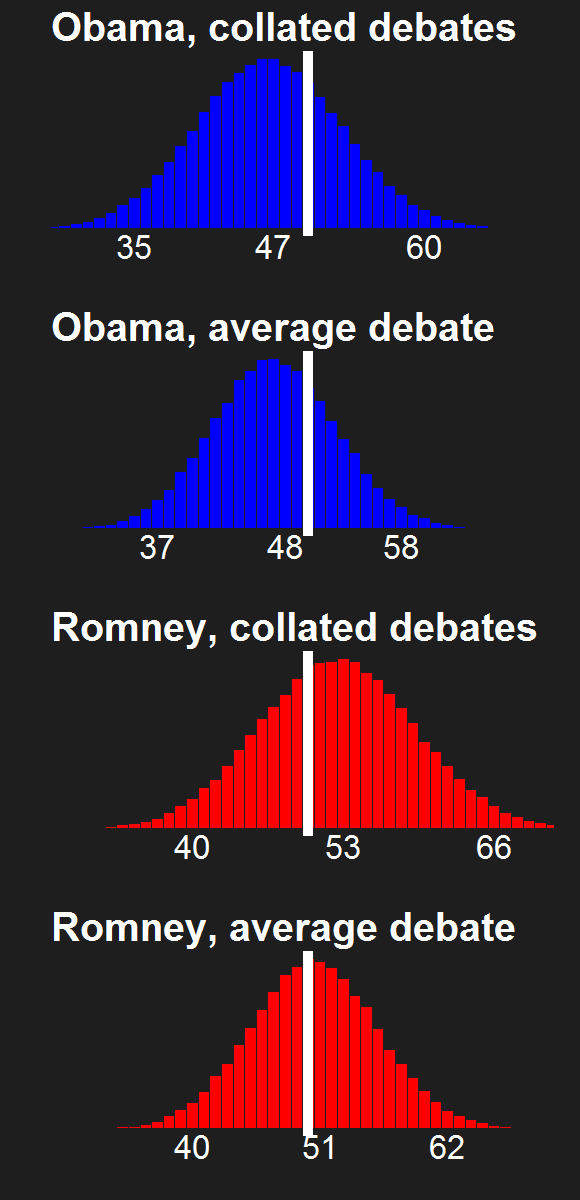
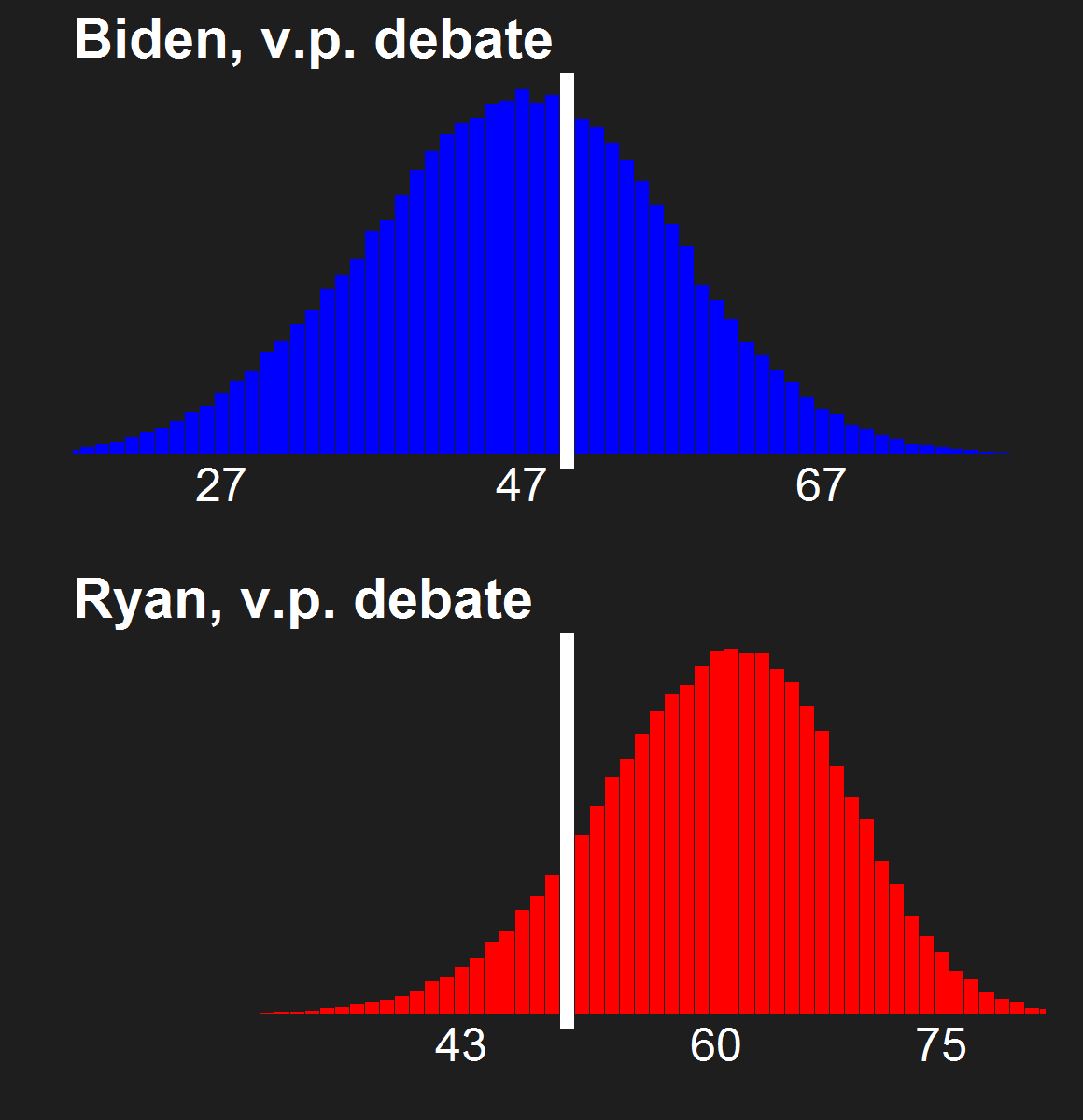
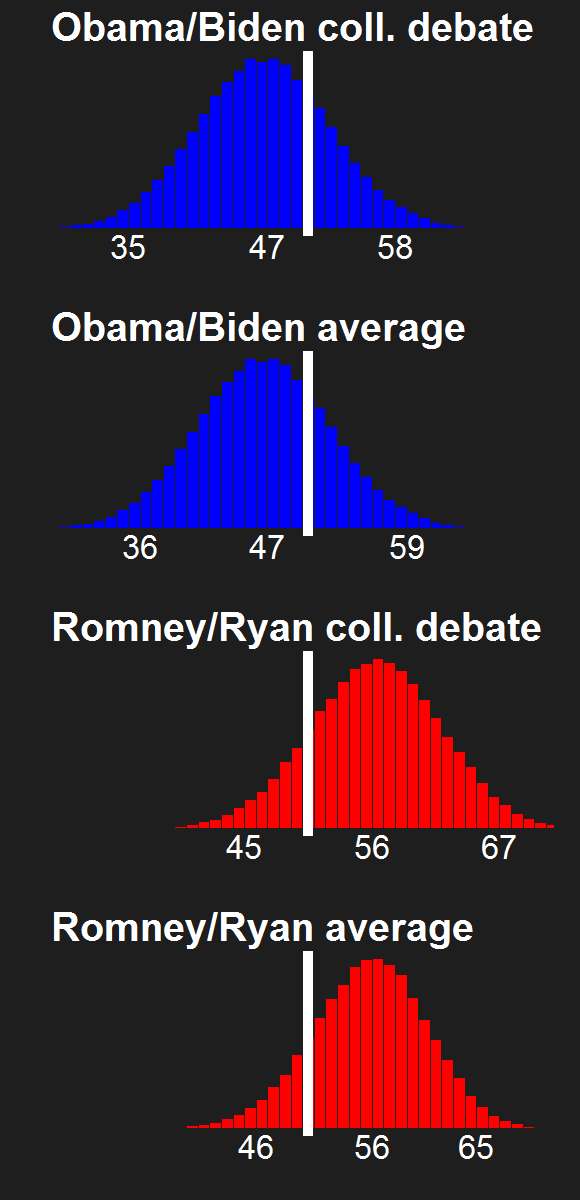
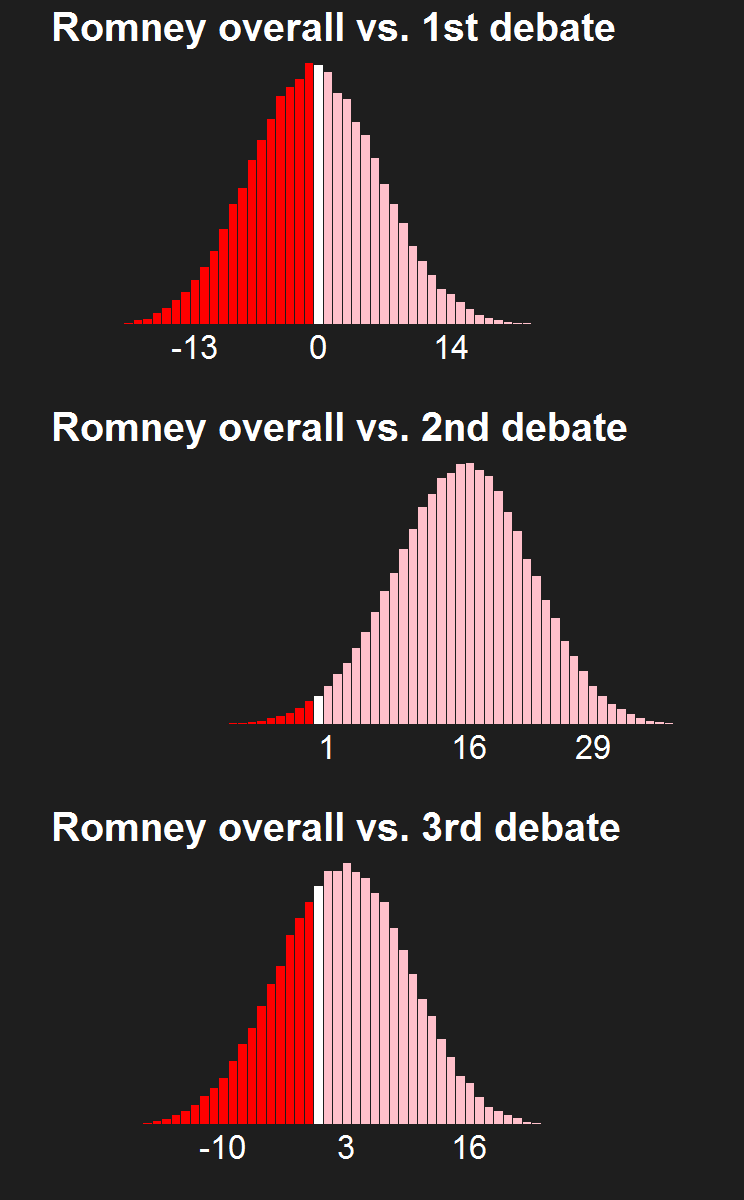
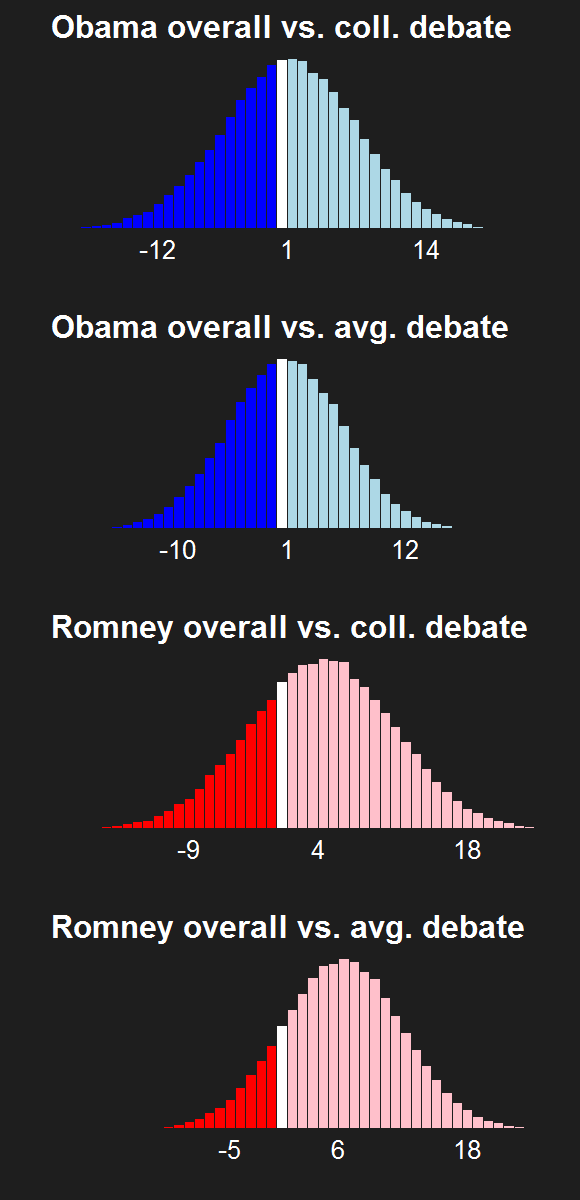
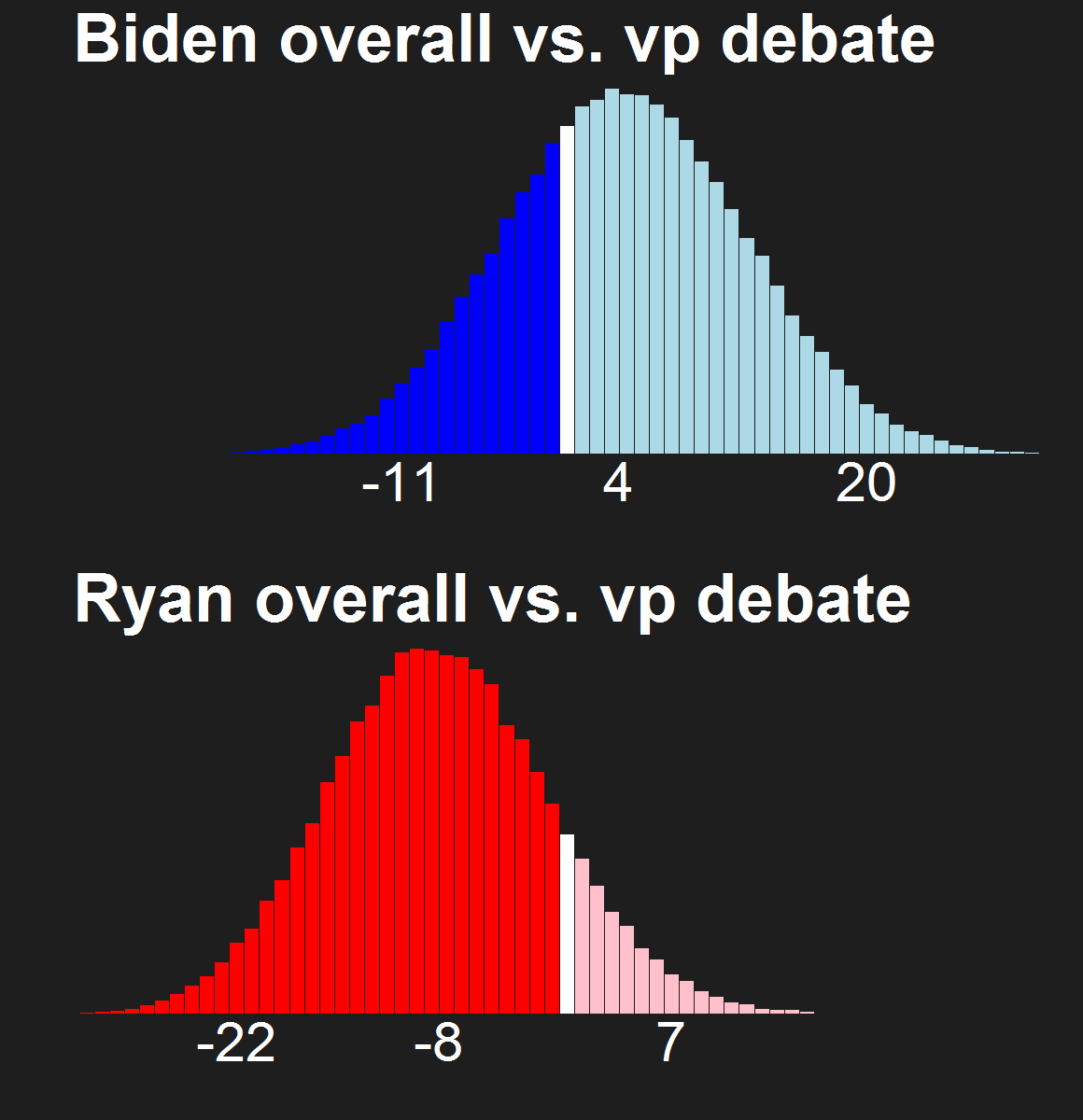
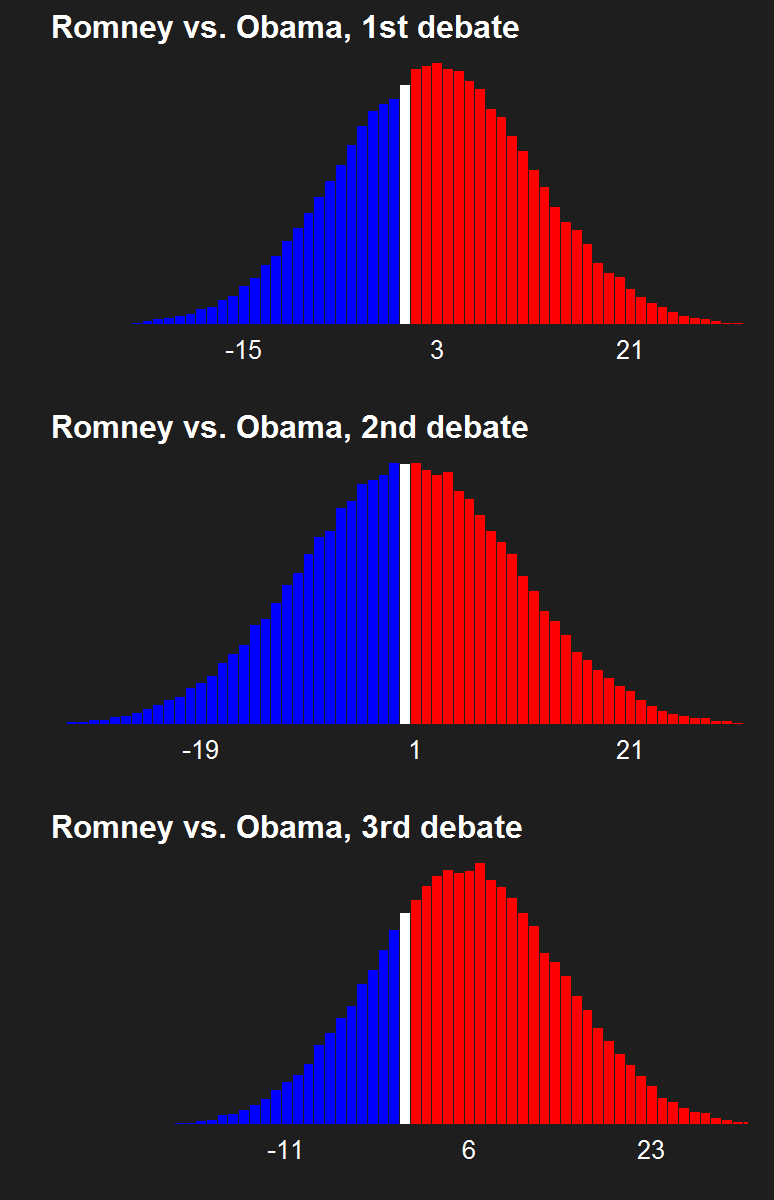
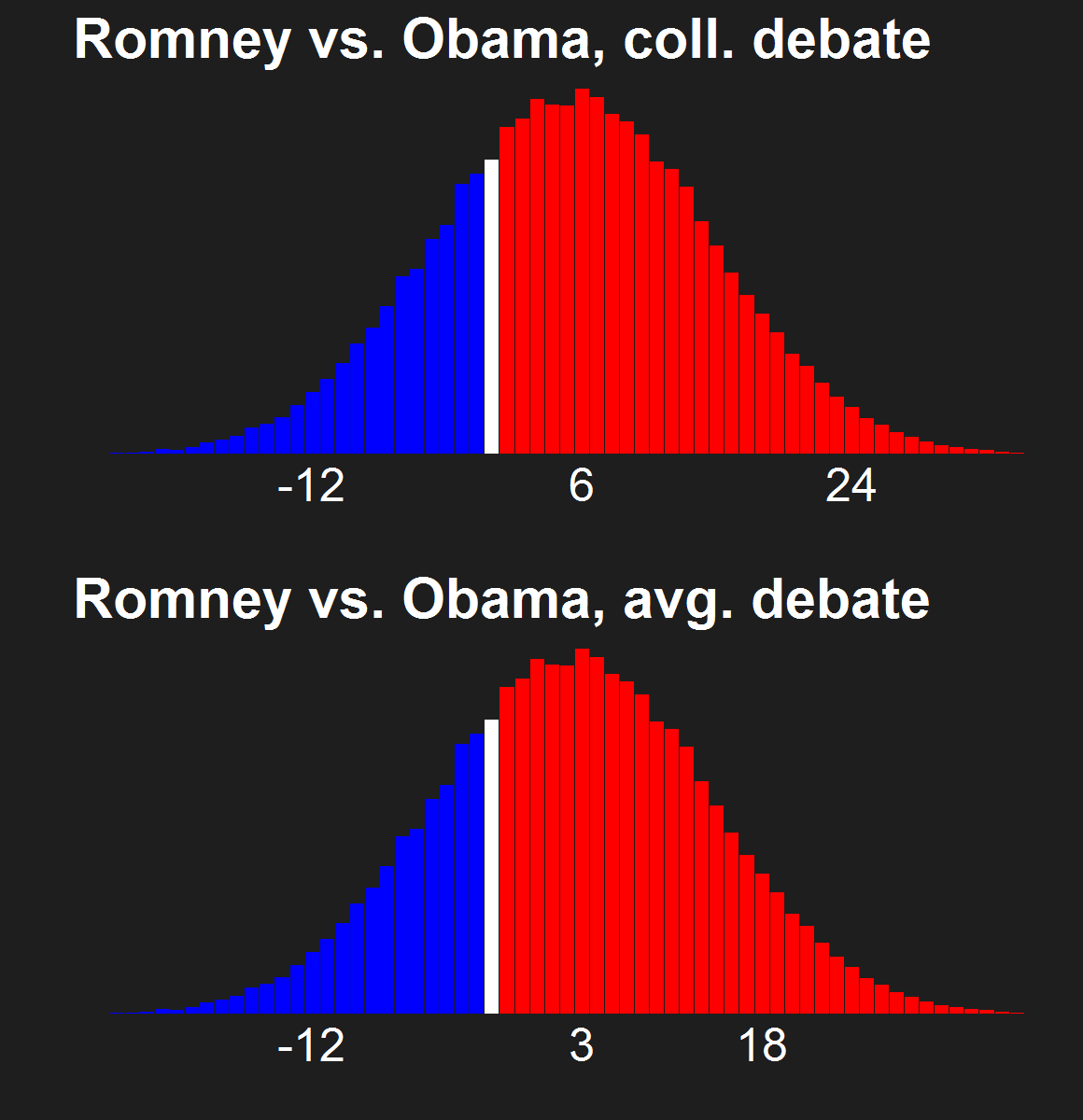
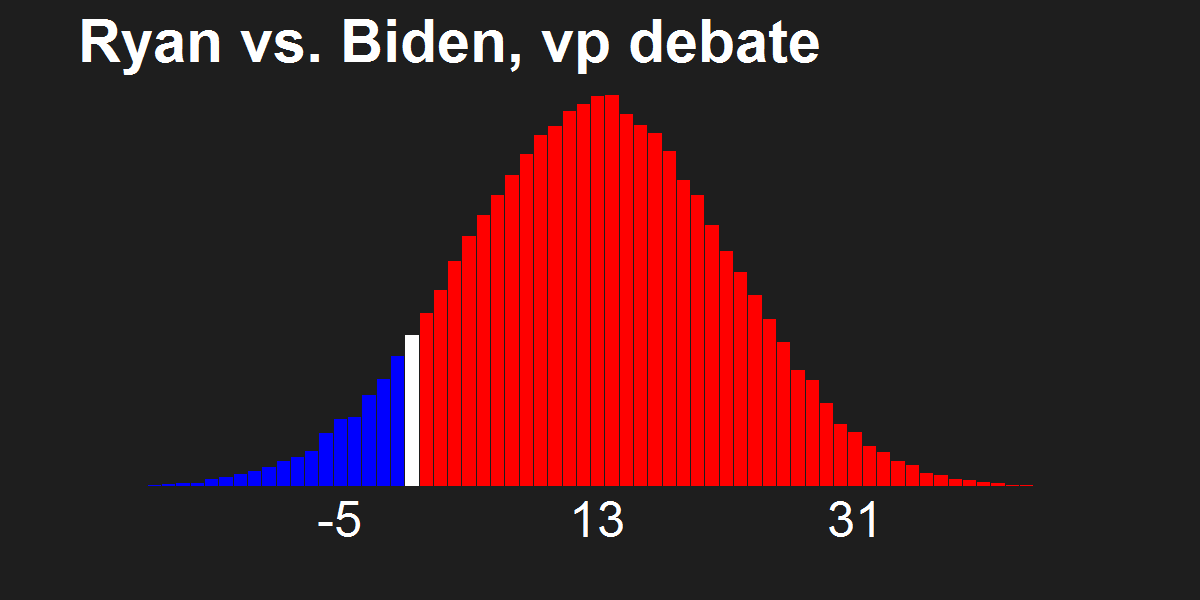
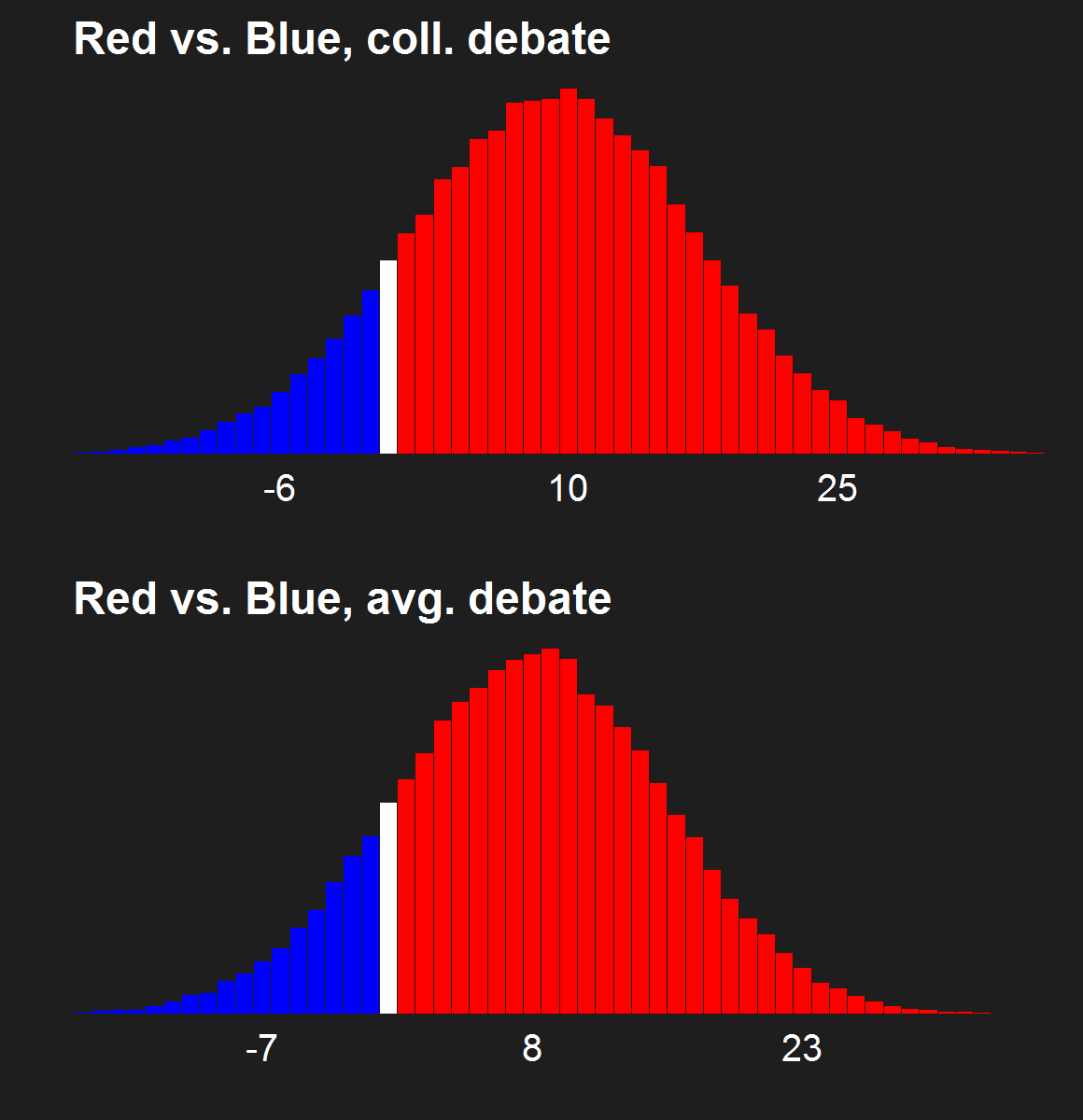
For the last few news cycles, Nate Silver (and by extension all election forecasters) faced intense but misguided scrutiny by pundits (especially conservative ones). His critics run the gamut from partisan charlatans to scared pundits clinging steadfastly to the relevance of their raconteur. It's fun to laugh at the innumerate, wishy washy arguments these people make. Yet a rational strain of the debate gets muffled by our collective cachinnation: the argument that Silver's model isn't perfect, simply because no model is likely to be perfect. I'll examine this strain of the debate and argue that we need to systematically compare and combine the results of the numerous election forecasting models that have cropped up in the last decade, and will crop up in the years to come.
This is a manifesto for better election prediction by comparing and contrasting prediction models. That's right. We need to aggregate the aggregators or, if you prefer, meta-analyze the meta-analyses.
The most extreme argument that Silver's forecasts are wrong comes from a model widely cited in the conservative media that predicts a landslide victory for Romney. Political scientists Kenneth Bickers and Michael Berry developed the model. Nate Silver has soundly questioned its merits, although only in a series of Tweets. In his Tweet-ique, Silver cited a model developed by Douglas Hibbs as a more meritorious example that favors Romney.
The critiques of Silver's model don't only come from those whose models forecast a Romney victory. Consistent variance exists among those forecasting an Obama win, as well. Drew Linzer's Votamatic forecast predicts a larger electoral vote victory for Obama than Silver's. Sam Wang's meta-margin and Darryl Holman's electoral vote predictions are consistently between Silver's and Linzer's. These differences have been in the tens of electoral votes, although the models are converging (with the exception of Linzer's) because we are so close to the election.
Similarly, variance exists among modelers in the odds they give for an Obama win. For example, today Wang gives over 99% probability to Obama winning the electoral vote. Holman's gives over 94% probability. Today, Silver gives about 80% probability to an Obama win. Those differences might look small as percents, but in terms of odds, they're big. Wang gives 99 to 1 odds that Obama will win, Holman gives about 16 to 1 odds, and Silver gives about 4 to 1 odds. From a bettor's perspective, those differences are effing huge because the odds are a strictly convex function of the probability of an event. That means the odds grow more and more quickly as an event becomes more probable. If you don't know what the Hell I am talking about, look at this graph of odds as a function of the percent chance of an event. See what I mean?
Anyway, those are just the forecasters I follow. HuffPo and WaPo now have their shiny-looking forecasts, and I'm sure a bunch of other outfits exist that I haven't even heard about. And you know there will be umpteen more forecasting blogs come election 2016, perhaps even by the mid-terms. Each of these forecasts will present a probabilistic picture of an election at a given point in time. They will use varying methods and, as we've already seen, they will likely produce varying results. Browsing each of them obsessively every day will give you a basic sense of how a campaign race is going. Just as well, it might confuse you. Furthermore, your personal biases and unchecked assumptions about what models are more right might cause you to subconsciously weight some models more heavily than others, leading to a conclusion that is about as justified as Wolf Blitzer's or Joe Scarborough's claim that it's a close race.
In the spirit of principled forecasting, subjective and subconscious impressions of the available election forecasts simply cannot stand, lest we instantaneously regress to the (hopefully) waning days of sensationalist campaign punditry. So what is the way forward?
Enter meta-meta-analysis. To understand what that is, you first need to understand what meta-analysis is. Many of the forecasters, like Silver and Wang and Holman and Linzer and Simon Jackman, use information from many polls to guide their models. Each poll is an independent experiment that measure the probability that someone will vote for a particular candidate. Some models, like Silver's, contrast these experiments by assigning a weight to the poll that is proportional to its historical accuracy. All election prediction models (except the ones that rely only on economic indicators to make predictions) also combine information from the separate polls to produce their predictions. An analysis that contrasts and/or combines the results of different studies is a meta-analysis.
But what if some of the analyses that you are combining and contrasting are themselves meta-analyses? That's what would happen if you took my advice and placed the sprawling set of election predictions models under systematic, quantitative scrutiny. I call such a study a meta-meta-analysis. I'm not the only one who calls it so. Recently, a paper in the Canadian Medical Association Journal did a meta-analysis of meta-analyses of medical research and found many of them problematic.
So why meta-meta-analysis? I've already argued that unsystematic review of election forecast models can lead us astray. A more positive argument is that election prediction meta-meta-analysis would provide us with a more complete, and possibly more accurate picture of the current state of a campaign race. The reason is that different election prediction models emphasize different aspects of the race. Some models include variables about the state of the economy. Among those, some models emphasize some variables over others or (in the case of the Berry/Bickers model) include an economic variable that no other models include. Other models take the polls at face value. The relative emphases on economic variables and polls represents one way in which forecasters differ in their approach to prediction.
Statisticians have argued that we must take into account our uncertainty in the best model to use when making predictions. Even if we could measure which of the models is the best one, statisticians argue, we shouldn't necessarily take that best model as the right answer. That would be as silly as always going with the answer of the pollster whose long-term accuracy is highest. While some election models might predict elections better than others, it is likely that none of them are perfectly accurate. It turns out that we might make better predictions by taking a weighted average of the results of the models available to us, with the weights proportional to our relative certainty that a given model is correct. If you want to geek out on this concept, read this excellent interview that Prashant Nair at PNAS did of statistician Adrian Raftery, who has applied model averaging methods to topics ranging from weather prediction to demographic forecasting.
I'm going out on a limb here to say that I'm a pioneer in the model averaging of election forecasting models. My meta-meta-analyses (which you can read here and here in reverse chronological order) are simple - almost stupidly simple. They combine only two models. They assume that the two models have equal predictive power in the absence of any evidence to the contrary. But they provide a first glimpse at the potential power of election prediction meta-meta-analysis, and present a simple method to average the electoral vote predictions of forecasters.
Where do we go from here? First, we need to compare more than two models. Yet election forecasters, particularly those who are licensed by major media companies, are likely wary of sharing their raw data for fear of being scooped (not so with at least two open source modelers, Sam Wang and Darryl Holman, who provide their raw electoral vote probability distributions for each forecast update). Second, we need to come up with a method to estimate our uncertainty in the predictive power of a given model (until then, I suggest we place equal weight on each model). Doing so, we can begin to make informed decisions about how to weight models' results when we average them. We would also have some measure of which models are "better". Third, we need to develop methods to effectively communicate the results of these meta-meta-analyses to the public so that people can understand what it all means (at least if they're not frothy-mouthed partisan buffoons or spotlight-grubbing dead-heat-arguing pundits).
So there you have it. A manifesto for meta-meta-analysis of election prediction models. I hope this message reaches election prediction modelers and convinces them that it is worthwhile to compromise our competing interests and Internet market share in the interest of making better predictions that result in a more informed public. I welcome your comments and criticism. Even if you'd never participate in this effort, election forecasters, at least give me your two cents.
Lastly, thanks to all the election forecasters for the important work that they do.
This is a manifesto for better election prediction by comparing and contrasting prediction models. That's right. We need to aggregate the aggregators or, if you prefer, meta-analyze the meta-analyses.
The most extreme argument that Silver's forecasts are wrong comes from a model widely cited in the conservative media that predicts a landslide victory for Romney. Political scientists Kenneth Bickers and Michael Berry developed the model. Nate Silver has soundly questioned its merits, although only in a series of Tweets. In his Tweet-ique, Silver cited a model developed by Douglas Hibbs as a more meritorious example that favors Romney.
The critiques of Silver's model don't only come from those whose models forecast a Romney victory. Consistent variance exists among those forecasting an Obama win, as well. Drew Linzer's Votamatic forecast predicts a larger electoral vote victory for Obama than Silver's. Sam Wang's meta-margin and Darryl Holman's electoral vote predictions are consistently between Silver's and Linzer's. These differences have been in the tens of electoral votes, although the models are converging (with the exception of Linzer's) because we are so close to the election.
Similarly, variance exists among modelers in the odds they give for an Obama win. For example, today Wang gives over 99% probability to Obama winning the electoral vote. Holman's gives over 94% probability. Today, Silver gives about 80% probability to an Obama win. Those differences might look small as percents, but in terms of odds, they're big. Wang gives 99 to 1 odds that Obama will win, Holman gives about 16 to 1 odds, and Silver gives about 4 to 1 odds. From a bettor's perspective, those differences are effing huge because the odds are a strictly convex function of the probability of an event. That means the odds grow more and more quickly as an event becomes more probable. If you don't know what the Hell I am talking about, look at this graph of odds as a function of the percent chance of an event. See what I mean?
Anyway, those are just the forecasters I follow. HuffPo and WaPo now have their shiny-looking forecasts, and I'm sure a bunch of other outfits exist that I haven't even heard about. And you know there will be umpteen more forecasting blogs come election 2016, perhaps even by the mid-terms. Each of these forecasts will present a probabilistic picture of an election at a given point in time. They will use varying methods and, as we've already seen, they will likely produce varying results. Browsing each of them obsessively every day will give you a basic sense of how a campaign race is going. Just as well, it might confuse you. Furthermore, your personal biases and unchecked assumptions about what models are more right might cause you to subconsciously weight some models more heavily than others, leading to a conclusion that is about as justified as Wolf Blitzer's or Joe Scarborough's claim that it's a close race.
In the spirit of principled forecasting, subjective and subconscious impressions of the available election forecasts simply cannot stand, lest we instantaneously regress to the (hopefully) waning days of sensationalist campaign punditry. So what is the way forward?
Enter meta-meta-analysis. To understand what that is, you first need to understand what meta-analysis is. Many of the forecasters, like Silver and Wang and Holman and Linzer and Simon Jackman, use information from many polls to guide their models. Each poll is an independent experiment that measure the probability that someone will vote for a particular candidate. Some models, like Silver's, contrast these experiments by assigning a weight to the poll that is proportional to its historical accuracy. All election prediction models (except the ones that rely only on economic indicators to make predictions) also combine information from the separate polls to produce their predictions. An analysis that contrasts and/or combines the results of different studies is a meta-analysis.
But what if some of the analyses that you are combining and contrasting are themselves meta-analyses? That's what would happen if you took my advice and placed the sprawling set of election predictions models under systematic, quantitative scrutiny. I call such a study a meta-meta-analysis. I'm not the only one who calls it so. Recently, a paper in the Canadian Medical Association Journal did a meta-analysis of meta-analyses of medical research and found many of them problematic.
So why meta-meta-analysis? I've already argued that unsystematic review of election forecast models can lead us astray. A more positive argument is that election prediction meta-meta-analysis would provide us with a more complete, and possibly more accurate picture of the current state of a campaign race. The reason is that different election prediction models emphasize different aspects of the race. Some models include variables about the state of the economy. Among those, some models emphasize some variables over others or (in the case of the Berry/Bickers model) include an economic variable that no other models include. Other models take the polls at face value. The relative emphases on economic variables and polls represents one way in which forecasters differ in their approach to prediction.
Statisticians have argued that we must take into account our uncertainty in the best model to use when making predictions. Even if we could measure which of the models is the best one, statisticians argue, we shouldn't necessarily take that best model as the right answer. That would be as silly as always going with the answer of the pollster whose long-term accuracy is highest. While some election models might predict elections better than others, it is likely that none of them are perfectly accurate. It turns out that we might make better predictions by taking a weighted average of the results of the models available to us, with the weights proportional to our relative certainty that a given model is correct. If you want to geek out on this concept, read this excellent interview that Prashant Nair at PNAS did of statistician Adrian Raftery, who has applied model averaging methods to topics ranging from weather prediction to demographic forecasting.
I'm going out on a limb here to say that I'm a pioneer in the model averaging of election forecasting models. My meta-meta-analyses (which you can read here and here in reverse chronological order) are simple - almost stupidly simple. They combine only two models. They assume that the two models have equal predictive power in the absence of any evidence to the contrary. But they provide a first glimpse at the potential power of election prediction meta-meta-analysis, and present a simple method to average the electoral vote predictions of forecasters.
Where do we go from here? First, we need to compare more than two models. Yet election forecasters, particularly those who are licensed by major media companies, are likely wary of sharing their raw data for fear of being scooped (not so with at least two open source modelers, Sam Wang and Darryl Holman, who provide their raw electoral vote probability distributions for each forecast update). Second, we need to come up with a method to estimate our uncertainty in the predictive power of a given model (until then, I suggest we place equal weight on each model). Doing so, we can begin to make informed decisions about how to weight models' results when we average them. We would also have some measure of which models are "better". Third, we need to develop methods to effectively communicate the results of these meta-meta-analyses to the public so that people can understand what it all means (at least if they're not frothy-mouthed partisan buffoons or spotlight-grubbing dead-heat-arguing pundits).
So there you have it. A manifesto for meta-meta-analysis of election prediction models. I hope this message reaches election prediction modelers and convinces them that it is worthwhile to compromise our competing interests and Internet market share in the interest of making better predictions that result in a more informed public. I welcome your comments and criticism. Even if you'd never participate in this effort, election forecasters, at least give me your two cents.
Lastly, thanks to all the election forecasters for the important work that they do.